kafka笔记
MQ可以解决同步通讯的问题,比如我们调用一个接口需要等这个接口做完所有的逻辑然后返回结果,而MQ可以存储我们的消息,上游直接返回,提高了系统的吞吐量,MQ中的消息一部处理。
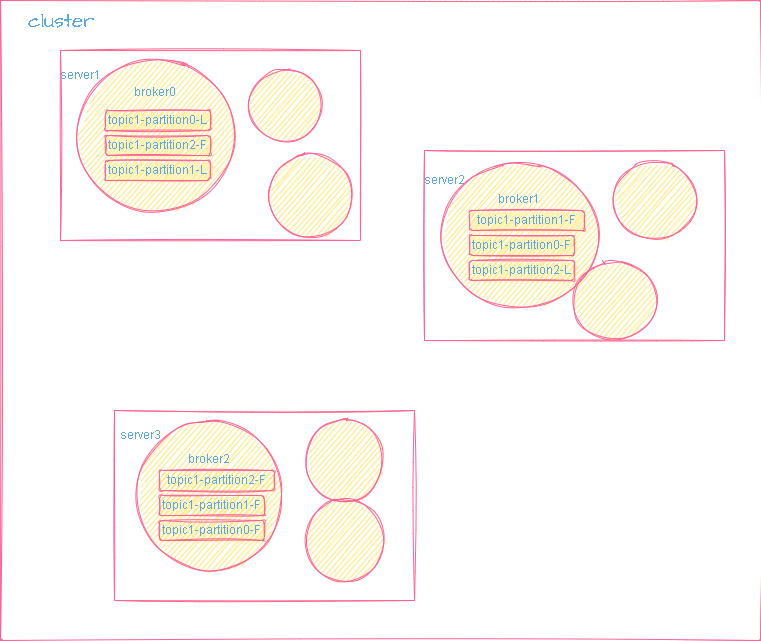
broker:需要指定监听端口,单机集群需要改端口号
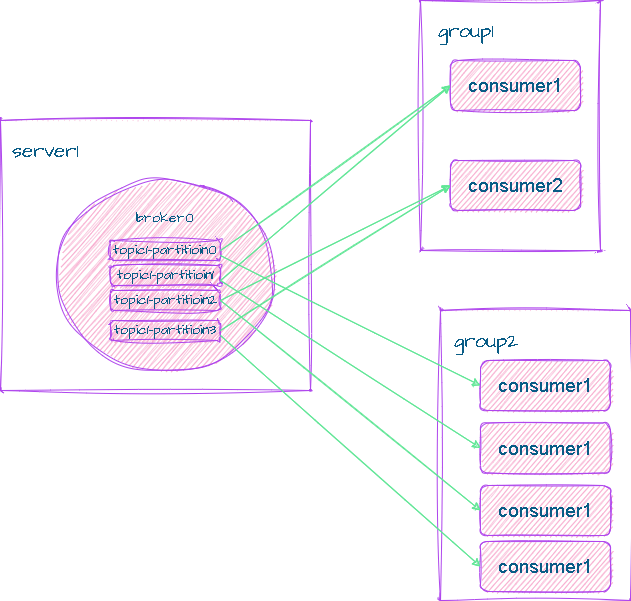
单播:一个组只能有一个消费者消费相同topic的同一条消息
多播:创建两个单播,即多个组,这样就可以有多个消费者消费相同topic的同一条消息
topic包含多条message,多条消息可以分布在不同的partition
分区的好处:分布式存储,可以并行写
一个partition只能被一个群组的一个cunsumer消费,从而保证了消费顺序。
消费组中消费者的数量不能比一个topic中partition的数量多,否则多出来的消费者不能消费消息
kafak发送消息时闭并不是每条消息都建立一个socket连接,是先将消息缓存,当消息达到设置参数如16K才会发送一次,如果超时未达到阈值,也会发送,这三个参数(buffer_memory_config,batch_size_config,linger_ms_config)可以手动配置
consumer可以设置手动和自动提交offset,默认为自动提交,如果consumer执行失败,消息则会消费失败。可以通过配置(auto_commit_config)修改此值来修改提交方式。
poll()方法是长连接,获取消息时,如果设置的时间内获取到${max_poll_records_config}条则退出轮询执行业务逻辑,如果小于${max_poll_records_config}则需要等待设置的时间后退出轮询。
将消费者剔除消费组,max_poll_interval_ms_config,两次poll的时间间隔,但是会触发rebalance机制,造成额外的性能开销。
消费者健康状态检查:消费者每隔1s会向集群发送心跳,如果超过10s未收到,则会被剔除消费组,触发rebalence。(可配置)
按时间段消费时间:可以根据时间获取offset,再根据offset消费消息。
新增的消费组默认从当前partition,latest最后一条消息offset+1开始消费,可以配置(auto_offset_reset_config)此项从头开始。
controller:
集群启动时zk创建一个临时序号节点,获得最小序号的那个broker充当controller
在isr集合中选举新的leader
broker增减,同步信息给其它contrllor
同步分区信息
Rebalance机制
前提是:消费者没有指明分区消费。当消费组里消费者和分区的关系发生变化,那么就会触发rebalance机制。
这个机制会重新调整消费者消费哪个分区。
在触发rebalance机制之前,消费者消费哪个分区有三种策略:
range:通过公示来计算某个消费者消费哪个分区
轮询:大家轮着消费
sticky:在触发了rebalance后,在消费者消费的原分区不变的基础上进行调整
HW和LEO
HW俗称高水位,HighWatermark的缩写,取一个partition对应的ISR中最小的LEO(log-end-offset)作为HW,consumer最多只能消费到HW所在的位置。另外每个replica都有HW,leader和follower各自负责更新自己的HW的状态。对于leader新写入的消息,consumer不能立刻消费,leader会等待该消息被所有ISR中的replicas同步后更新HW,此时消息才能被consumer消费。这样就保证了如果leader所在的broker失效,该消息仍然可以从新选举的leader中获取。